When you find that the standard TreeModels are not sufficiently powerful for your application needs, you can use the GenericTreeModel to build your own custom TreeModel in Python. Creating a GenericTreeModel may be useful when there are performance issues with the standard TreeStore and ListStore objects or when you want to directly interface to an external data source (say, a database or filesystem) to save copying the data into and out of a TreeStore or ListStore.
With the GenericTreeModel you build and manage your data model and provide external access though the standard TreeModel interface by defining a set of class methods. PyGTK implements the TreeModel interface and arranges for your TreeModel methods to be called to provide the actual model data.
The implementation details of your model should be kept completely hidden from the external application. This means that the way that your model identifies, stores and retrieves data is unknown to the application. In general the only information that is saved outside your GenericTreeModel are the row references that are wrapped by the external TreeIters. And these references are not visible to the application.
Let's examine in detail the GenericTreeModel interface that you have to provide.
The GenericTreeModel interface consists of the following methods that must be implemented in your custom tree model:
def on_get_flags(self) def on_get_n_columns(self) def on_get_column_type(self, index) def on_get_iter(self, path) def on_get_path(self, rowref) def on_get_value(self, rowref, column) def on_iter_next(self, rowref) def on_iter_children(self, parent) def on_iter_has_child(self, rowref) def on_iter_n_children(self, rowref) def on_iter_nth_child(self, parent, n) def on_iter_parent(self, child)You should note that these methods support all of the TreeModel interface including:
def get_flags() def get_n_columns() def get_column_type(index) def get_iter(path) def get_iter_from_string(path_string) def get_string_from_iter(iter) def get_iter_root() def get_iter_first() def get_path(iter) def get_value(iter, column) def iter_next(iter) def iter_children(parent) def iter_has_child(iter) def iter_n_children(iter) def iter_nth_child(parent, n) def iter_parent(child) def get(iter, column, ...) def foreach(func, user_data)To illustrate the use of the GenericTreeModel I'll change the filelisting.py example program and show how the interface methods are created. The filelisting-gtm.py program displays the files in a folder with a pixbuf indicating if the file is a folder or not, the file name, the file size, mode and time of last change.
The on_get_flags() method should return a value that is a combination of:
| gtk.TREE_MODEL_ITERS_PERSIST | TreeIters survive all signals emitted by the tree. |
| gtk.TREE_MODEL_LIST_ONLY | The model is a list only, and never has children |
If your model has row references that are valid over row changes (reorder, addition, deletion) then set gtk.TREE_MODEL_ITERS_PERSIST. Likewise if your model is a list only then set gtk.TREE_MODEL_LIST_ONLY. Otherwise, return 0 if your model doesn't have persistent row references and it's a tree model. For our example, the model is a list with persistent TreeIters.
def on_get_flags(self):
return gtk.TREE_MODEL_LIST_ONLY|gtk.TREE_MODEL_ITERS_PERSIST
|
The on_get_n_columns() method should return the number of columns that your model exports to the application. Our example maintains a list of column types so we return the length of the list:
class FileListModel(gtk.GenericTreeModel):
...
column_types = (gtk.gdk.Pixbuf, str, long, str, str)
...
def on_get_n_columns(self):
return len(self.column_types)
|
The on_get_column_type() method should return the type of the column with the specified index. This method is usually called from a TreeView when its model is set. You can either create a list or tuple containing the column data type info or generate it on-the-fly. In our example:
def on_get_column_type(self, n):
return self.column_types[n]
|
The GenericTreeModel interface converts the Python type to a GType so the following code:
flm = FileListModel() print flm.on_get_column_type(1), flm.get_column_type(1) |
would print:
<type 'str'> <GType gchararray (64)> |
The following methods use row references that are kept as private data in a TreeIter. The application can't see the row reference in a TreeIter so you can use any unique item you want as a row reference. For example in a model containing rows as tuples you could use the tuple id as the row reference. Another example would be to use a filename as the row reference in a model representing files in a directory. In both these cases, the row reference is unchanged by model changes so the TreeIters could be flagged as persistent. The PyGTK GenericTreeModel application interface will extract your row references from TreeIters and wrap your row references in TreeIters as needed.
In the following methods rowref refers to an internal row reference.
The on_get_iter() method should return an rowref for the tree path specified by path. The tree path will always be represented using a tuple. Our example uses the file name string as the rowref. The file names are kept in a list in the model so we take the first index of the path as an index to the file name:
def on_get_iter(self, path):
return self.files[path[0]]
|
You have to be consistent in your row reference usage since you'll get a row reference back in method calls from the GenericTreeModel methods that take TreeIter arguments: on_get_path(), on_get_value(), on_iter_next(), on_iter_children(), on_iter_has_child(), on_iter_n_children(), on_iter_nth_child() and on_iter_parent().
The on_get_path() method should return a tree path given a rowref. For example, continuing the above example where the file name is used as the rowref, you could define the on_get_path() method as:
def on_get_path(self, rowref):
return self.files.index(rowref)
|
This method finds the index of the list containing the file name in rowref. It's obvious from this example that a judicious choice of row reference will make the implementation more efficient. You could, for example, use a Python dict to map rowref to a path.
The on_get_value() method should return the data stored at the row and column specified by rowref and column. For our example:
def on_get_value(self, rowref, column):
fname = os.path.join(self.dirname, rowref)
try:
filestat = statcache.stat(fname)
except OSError:
return None
mode = filestat.st_mode
if column is 0:
if stat.S_ISDIR(mode):
return folderpb
else:
return filepb
elif column is 1:
return rowref
elif column is 2:
return filestat.st_size
elif column is 3:
return oct(stat.S_IMODE(mode))
return time.ctime(filestat.st_mtime)
|
has to extract the associated file information and return the appropriate value depending on which column is specified.
The on_iter_next() method should return a row reference to the row (at the same level) after the row specified by rowref. For our example:
def on_iter_next(self, rowref):
try:
i = self.files.index(rowref)+1
return self.files[i]
except IndexError:
return None
|
The index of the rowref file name is determined and the next file name is returned or None is returned if there is no next file.
The on_iter_children() method should return a row reference to the first child row of the row specified by rowref. If rowref is None, a reference to the first top level row is returned. If there is no child row None is returned. For our example:
def on_iter_children(self, rowref):
if rowref:
return None
return self.files[0]
|
Since the model is a list model only the top level (rowref=None) can have child rows. None is returned if rowref contains a file name.
The on_iter_has_child() method should return TRUE if the row specified by rowref has child rows; FALSE otherwise. Our example returns FALSE since no row can have a child:
def on_iter_has_child(self, rowref):
return False
|
The on_iter_n_children() method should return the number of child rows that the row specified by rowref has. If rowref is None, the number of top level rows is returned. Our example returns 0 if rowref is not None:
def on_iter_n_children(self, rowref):
if rowref:
return 0
return len(self.files)
|
The on_iter_nth_child() method should return a row reference to the nth child row of the row specified by parent. If parent is None, a reference to the nth top level row is returned. Our example returns the nth top level row reference if parent is None. Otherwise None is returned:
def on_iter_nth_child(self, rowref, n):
if rowref:
return None
try:
return self.files[n]
except IndexError:
return None
|
The on_iter_parent() method should return a row reference to the parent row of the row specified by rowref. If rowref points to a top level row, None should be returned. Our example always returns None assuming that rowref must point to a top level row:
def on_iter_parent(child):
return None
|
This example is put together in the filelisting-gtm.py program. Figure 14.11, “Generic TreeModel Example Program” shows the result of running the program.
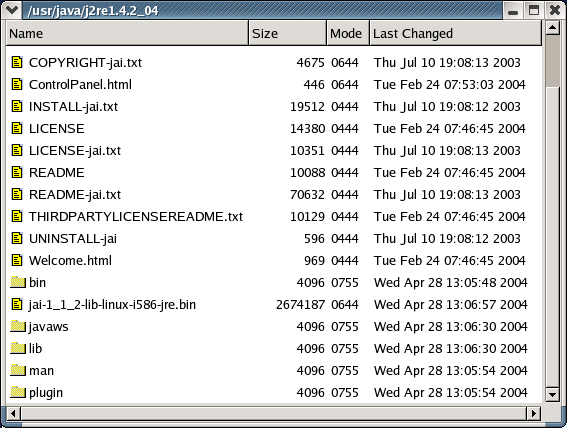
The filelisting-gtm.py program calculates the list of file names while creating a FileListModel instance. If you want to check for new files periodically and add or remove files from the model you could either create a new FileListModel for the same folder or you could add methods to add and remove rows in the model. Depending on the type of model you are creating you would need to add methods similar to those in the TreeStore and ListStore models:
- insert()
- insert_before()
- insert_after()
- prepend()
- append()
- remove()
- clear()
Of course not all or any of these need to be implemented. You can create your own methods that are more closely related to your model.
Using the above example program to illustrate adding methods for removing and adding files, let's implement the methods:
def remove(iter) def add(filename)The remove() method removes the file specified by iter. In addition to removing the row from the model the method also should remove the file from the folder. Of course, if the user doesn't have the permissions to remove the file then the row shouldn't be removed either. For example:
def remove(self, iter):
path = self.get_path(iter)
pathname = self.get_pathname(path)
try:
if os.path.exists(pathname):
os.remove(pathname)
del self.files[path[0]]
self.row_deleted(path)
except OSError:
pass
return
|
The method is passed a TreeIter that has to be converted to a path to use to retrieve the file path using the method get_pathname(). It's possible that the file has already been removed so we check if it exists before trying to remove it. If an OSError exception is thrown during the file removal it's probably because the file is a directory or the user doesn't have sufficient privilege to remove it. Finally, the file is removed and the "row-deleted" signal is emitted from the rows_deleted() method. The "file-deleted" signal notifies the TreeViews using the model that the model has changed so that they can update their internal state and display the revised model.
The add() method needs to create a file with the given name in the current folder. If the file was created its name is added to the list of files in the model. For example:
def add(self, filename):
pathname = os.path.join(self.dirname, filename)
if os.path.exists(pathname):
return
try:
fd = file(pathname, 'w')
fd.close()
self.dir_ctime = os.stat(self.dirname).st_ctime
files = self.files[1:] + [filename]
files.sort()
self.files = ['..'] + files
path = (self.files.index(filename),)
iter = self.get_iter(path)
self.row_inserted(path, iter)
except OSError:
pass
return
|
This simple example makes sure that the file doesn't exist then tries to open the file for writing. If successful, the file is closed and the file name sorted into the list of files. The path and TreeIter for the added file row are retrieved to use in the row_inserted() method that emits the "row-inserted" signal. The "row-inserted" signal is used to notify the TreeViews using the model that they need to update their internal state and revise their display.
The other methods mentioned above (for example, append and prepend) don't make sense for the example since the model keeps the file list sorted.
Other methods that may be worth implementing in a TreeModel subclassing the GenericTreeModel are:
- set_value()
- reorder()
- swap()
- move_after()
- move_before()
Implementing these methods is similar to the above methods. You have to synchronize the model with the external state and then notify the TreeViews if the model has changed. The following methods are used to notify the TreeViews of model changes by emitting the appropriate signal:
def row_changed(path, iter) def row_inserted(path, iter) def row_has_child_toggled(path, iter) def row_deleted(path) def rows_reordered(path, iter, new_order)One of the problems with the GenericTreeModel is that TreeIters hold a reference to a Python object returned from your custom tree model. Since the TreeIter may be created and initialized in C code and live on the stack, it's not possible to know when the TreeIter has been destroyed and the Python object reference is no longer being used. Therefore, the Python object referenced in a TreeIter has by default its reference count incremented but it is not decremented when the TreeIter is destroyed. This ensures that the Python object will not be destroyed while being used by a TreeIter and possibly cause a segfault. Unfortunately the extra reference counts lead to the situation that, at best, the Python object will have an excessive reference count and, at worst, it will never be freed even when it is not being used. The latter case leads to memory leaks and the former to reference leaks.
To provide for the situation where the custom TreeModel holds a reference to the Python object until it is no longer available (i.e. the TreeIter is invalid because the model has changed) and there is no need to leak references, the GenericTreeModel has the "leak-references" property. By default "leak-references" is TRUE to indicate that the GenericTreeModel will leak references. If "leak-references" is set to FALSE, the reference count of the Python object will not be incremented when referenced in a TreeIter. This means that your custom TreeModel must keep a reference to all Python objects used in TreeIters until the model is destroyed. Unfortunately, even this cannot protect against buggy code that attempts to use a saved TreeIter on a different GenericTreeModel. To protect against that case your application would have to keep references to all Python objects referenced from a TreeIter for any GenericTreeModel instance. Of course, this ultimately has the same result as leaking references.
In PyGTK 2.4 and above the invalidate_iters() and iter_is_valid() methods are available to help manage the TreeIters and their Python object references:
generictreemodel.invalidate_iters() result = generictreemodel.iter_is_valid(iter) |
These are particularly useful when the "leak-references" property is set to FALSE. Tree models derived from GenericTreeModel are protected from problems with out of date TreeIters because the iters are automatically checked for validity with the tree model.
If a custom tree model doesn't support persistent iters (i.e. gtk.TREE_MODEL_ITERS_PERSIST is not set in the return from the TreeModel.get_flags() method), it can call the invalidate_iters() method to invalidate all its outstanding TreeIters when it changes the model (e.g. after inserting a new row). The tree model can also dispose of any Python objects, that were referenced by TreeIters, after calling the invalidate_iters() method.
Applications can use the iter_is_valid() method to determine if a TreeIter is still valid for the custom tree model.
The ListStore and TreeStore models support the TreeSortable, TreeDragSource and TreeDragDest interfaces in addition to the TreeModel interface. The GenericTreeModel only supports the TreeModel interface. I believe that this is because of the direct reference of the model at the C level by TreeViews and the TreeModelSort and TreeModelFilter models. To create and use TreeIters requires C glue code to interface with the Python custom tree model that has the data. That glue code is provided by the GenericTreeModel and there appears to be no alternative purely Python way of doing it because the TreeViews and the other models call the GtkTreeModel functions in C passing their reference to the custom tree model.
The TreeSortable interface would need C glue code as well to work with the default TreeViewColumn sort mechanism as explained in Section 14.2.9, “Sorting TreeModel Rows”. However a custom model can do its own sorting and an application can manage the use of sort criteria by handling the TreeViewColumn header clicks and calling the custom tree model sort methods. The model completes the update of the TreeViews by emitting the "rows-reordered" signal using the TreeModel's rows_reordered() method. Thus the GenericTreeModel probably doesn't need to implement the TreeSortable interface.
Likewise, the GenericTreeModel doesn't have to implement the TreeDragSource and TreeDragDest interfaces because the custom tree model can implement its own drag and drop interfaces and the application can handle the appropriate TreeView signals and call the custom tree model methods as needed.
I believe that the GenericTreeModel should only be used as a last resort. There are powerful mechanisms in the standard group of TreeView objects that should be sufficient for most applications. Undoubtedly there are applications which may require the use of the GenericTreeModel but you should attempt to first use the following instead:
| Cell Data Functions | As illustrated in Section 14.4.5, “Cell Data Function”, cell data functions can be used to modify and even synthesize the data for a TreeView column display. You can effectively create as many display columns with generated data as you wish. This gives you a great deal of control over the presentation of data from an underlying data source. |
| TreeModelFilter | In PyGTK 2.4, the TreeModelFilter as described in Section 14.10.2, “TreeModelFilter” provides a great degree of control over the display of the columns and rows of a child TreeModel including presenting just the child rows of a row. Data columns can be synthesized similar to using Cell Data Functions but here the model appears to be a TreeModel with the number and type of columns specified whereas a cell data function leaves the model columns unchanged and just modifies the display in a TreeView. |
If a GenericTreeModel must be used you should be aware that:
- the entire TreeModel interface must be created and made to work as documented. There are subtleties that can lead to bugs. By contrast, the standard TreeModels are thoroughly tested.
- managing the references of Python objects used by TreeIters can be difficult especially for long running programs with lots of variety of display.
- an interface has to be developed for adding, deleting and changing the contents of rows. There is some awkwardness with the mapping of TreeIters to the Python objects and model rows in this interface.
- there is significant effort in developing sortable and drag and drop interfaces. The application probably needs to be involved in making these interfaces fully functional.